


Section: New Results
Representation and compression of large volumes of visual data
3d representations for multi-view video sequences
Participants : Christine Guillemot, Vincent Jantet.
Multi-view plus depth video content represent very large volumes of input data wich need to be compressed for storage and tranmission to the rendering device. The huge amount of data contained in multi-view sequences indeed motivates the design of efficient representation and compression algorithms. In collaboration with INSA/IETR (Luce Morin), we have studied layered depth image (LDI) and layered depth video (LDV) representations as a possible compact representation format of multi-view video plus depth data. LDI give compact representions of 3D objects, which can be efficiently used for photo-realistic image-based rendering (IBR) of different scene viewpoints, even with complex scene geometry. The LDI extends the 2D+Z representation, but instead of representing the scene with an array of depth pixels (pixel color with associated depth values), each position in the array may store several depth pixels, organised into layers.
Various approaches exist to construct LDI, which all organize layers by visibility. The first layer contains all pixels visible from a chosen reference viewpoint. The other layers contain pixels hidden by objects in previous layers. With classical construction solutions, each layer may contain pixels from the background and pixels from objects in a same neighbourhood, creating texture and depth discontinuities within the same layer. These discontinuities are blurred during the compression process which in turn significantly reduces the rendering quality.
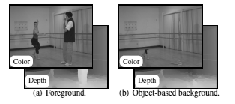
We have thus developed a novel object-based LDI representation which is more tolerant to compression artifacts, as well as being compatible with fast mesh-based rendering techniques [34] . This representation organises LDI pixels into two separate layers (foreground and background) to enhance depth continuity (see Fig.6 ). The construction of this object-based LDI makes use of a foreground-background region-growing segmentation algorithm followed by inpainting of both colour and texture images to have a complete background layer (without the holes corresponding to disocclusion areas). The costly inpainting algorithm is thus processed once, during the LDI classification, and not during each view synthesis, which helps to speed up the rendering step.
|

From sparse to spread representations
Participant : Jean Jacques Fuchs.
Sparse representations, where one seeks to represent a vector on a redundant basis using the smallest number of basis vectors, appear to have numerous applications. The other extreme, where one seeks a representation that uses all the basis vectors, might be of interest if one manages to spread the information nearly equally over all of them. Minimizing the -norm of the vector of weights is one way to find such a representation. Properties of the solution and a dedicated fast algorithm have been developed. While the application of such models in robust data coding and in improving achievable data rates over amplitude constrained channels seems to be wishful thinking, its use in indexing techniques appears to be promising. In this context, one further replaces the optimal vector by its sign vector (potentially associated with a re-evaluated scalar weight) to get a binary vector that is not only cheap to store and (somehow) easy to search for but also allows for an explicit reconstruction unlike all other Hamming embedding functions used to map real vectors into binary vectors.
On-line dictionary learning methods for prediction
Participants : Christine Guillemot, Mehmet Turkan.
One crucial question to the problem of sparse approximation, and hence also of prediction based on sparse approximation, is the choice of the dictionary. Various advanced dictionary learning schemes have been proposed in the literature for the sparse signal approximation problem, so that the dictionary used is well suited to the data at hand. The popular dictionary learning algorithms include the K-SVD, the Method of Optimal Directions (MOD), Sparse Orthonormal Transforms (SOT), and (Generalized) Principle Component Analysis (PCA). However, the above learning methods are often used off-line since their computational complexity, which results from the number and the dimension of training samples, makes them inappropriate for online learning. In addition, these methods are adapted to the learning of basis to be used for approximating input data vectors, but not to the problem of predicting unknown samples from noisy observed samples in a causal neighborhood.
In 2011, we have developed a method for on-line training dictionaries adapted to the prediction problem [41] . Let A be the input dictionary, which is divided into two sub-dictionaries: and . The goal is to have a simple on-line dictionary learning method which is adapted to the prediction problem, i.e., which will learn both sub-dictionaries so that sparse vectors found by approximating the known samples (the template) using the first sub-dictionary () will also lead to a good approximation of the block to be predicted when used together with the second sub-dictionary (). When dealing with the prediction problem, the sparse signal approximation is indeed first run with a set of masked basis functions (dictionary ), the masked samples corresponding to the location of the pixels to be predicted. The principle of the approach is to first search for the linear combination of basis functions which best approximates known sample values in a causal neighborhood, and keep the same linear combination of basis functions, but this time with the unmasked samples (dictionary ) to approximate the block to be predicted. The decoder similarly runs the algorithm with the masked basis functions and taking the previously decoded neighborhood as the known support. The use of masked basis functions converts the complete approximation problem into an overcomplete approximation problem. Because of its simplicity, of the limited number of training samples it requires, can be used for online learning of dictionaries, i.e. while doing the block-wise encoding of the image. The training samples are all possible previously coded/decoded texture patches (blocks of pixels) within a search window located in a causal neighborhood of the block to be predicted.
Neighbor embedding methods for image prediction and inpainting
Participants : Christine Guillemot, Mehmet Turkan.
The problem of texture prediction as well as image inpainting can be regarded as a problem of texture synthesis. Given observations, or known samples in a spatial neighborhood, the goal is to estimate unknown samples of the block to be predicted or of the patch to be filled in inpainting. We have developed texture prediction methods as well as a new inpainting algorithm based on neighbor embedding techniques which come from the area of data dimensionality reduction. The methods which we have more particularly considered are Locally Linear Embedding (LLE) and Non-negative Matrix Factorization (NMF). The first step in the developed methods consists in searching, within the known part of the image, for the nearest (KNN) patches to the set of known samples in the neighborhood of the block to be predicted or of samples to be estimated in the context of inpainting. This first step can be seen as constructing a dictionary matrix by stacking in the matrix columns the vectorized K-NN texture patches. The non-negative dictionary matrix , is formed by K nearest neighbors to the vector formed by the known samples in the neighborhood of the samples to be predicted. These K nearest neighbors are texture patches of the same shape taken from the known part of the image. This dictionary can then be used for approximating the known samples by masking the rows of the matrix which correspond to the position of the unknown samples, solving a least squares problem under the constraint of sum-to-one of the wieghts in the case of LLE, or under the constraint of non-negativity of the weights for NMF. It is actually a variant of NMF since one of the components matrices is fixed (the one corresponding to the dictionary matrix) and only the matrix containing the weights of the linear approximation must then be found. The approaches are thus intended to explore the properties of the manifolds on which the input texture patches are assumed to reside. The underlying assumption is that the corresponding uncomplete and complete patches have similar neighborhoods on some nonlinear manifolds. The new prediction methods give RD performances which are signficantly better than the ones given by the H.264 Intra prediction modes, in particular for highly textured images [21] , the highest gain being achieved with NMF.
A new examplar-based inpainting algorithm using neighbor embedding techniques has been developed. A new priority order has been proposed in order to inapint first patches containing structures or contour information. The methods have also been shown to enhance the quality of inpainted images when compared to classical examplar-based solutions using simple template matching techniques to estimate the missing pixels, (see Fig. 7 ).
|



Lossless coding for medical images
Participants : Claude Labit, Jonathan Taquet.
Last year, we developped a hierarchical oriented prediction (HOP) algorithm, for resolution scalable lossless and near lossless compression of biomedical images. In 2011, the algorithm has been slightly improved with an iterative optimization of the predictors in order to get better results on less noisy/smooth images [39] .
Recently, there have been a growing interest for the compression of an emerging imaging modality : the virtual microscopy (VM). It is used in anatomopathology and may produce huge images of more than 1 Gigabytes. We have studied the efficiency for lossless and lossy compression of our previously developped algorithms HOP and OWD (optimized wavelet decomposition) and of two extensions of OWD : near-lossless and/or region of interest (ROI) coding. The lossless results, which are slightly better than JPEG-LS and JPEG-2000 standards with about 3:1 compression ratio, show that lossless compression is not suited to VM. By compressing only the information area (ROI) which represents about 20 percents of the size of test images, 9:1 ratio could be obtained, and combined with near-lossless approach, depending on the required quality, ratio can reach 17:1 with no visual losses to more than 30:1 with some visual losses (or approximately about 6:1 for ROI only data). We have concluded that it would probably be better to use lossy or efficient quality scalable compression. Because those images have specific contents (cellular tissus for example) we have also introduced and investigated new learning based methods. We have developped an optimization process for designing multiple KLT (Karhunen-Loeve Transform) in order to get orthonormal bases that are optimal for decorrelation and quality scalability. This learning approach has been applied as an a-posteriori transform of a wavelet decomposition in order to propose transforms with no blocking artefacts. A fully quality-scalable coding algorithm allows to obtain interesting PSNR improvements compared to the optimized coding process of JPEG-2000. Gain is around 0.5 dB for 16:1 compression of ROI only data, and more than 1 dB for 8:1 compression ratio.